
Hack Reactor Week 9 and 10 Review
Senior Design Capstone - Scaling a Postgres backend architecture to thousands of clients per second

I'm attending the Hack Reactor 12 Week immersive coding bootcamp from 11APR to 8JUL in an effort to develop my programming skills to offer a wider range of services to my clients. The schedule is jam packed with 11 hours of coding content 6 days a week Mon-Sat. I'll be keeping a journal of my experiences with the program here.
These two weeks are all about our Senior Design Capstone, which involves architecting the backend of the Front End Capstone app and scaling it for massive user growth. The executive summary, which we practice reciting to potential employers, goes a little like this:
“I worked on the reviews service for e-commerce website. I experienced strong tradeoffs between time spent fine-tuning db queries and time-to-MVP. A divide-and-conquer approach to query writing combined with load-balancing, caching, and indexing was a an effective way to quickly obtain MVP. However, consolidating multiple queries into one was the best way to actually scale my service despite taking more time and adding complexity.”
Or a resume bullet that sounds like this:
Horizontally scaled backend service for random sampling of >1M record reviews endpoint to achieve >1000 RPS by optimizing query times and building 4-server load balancer with NGINX in AWS.
RPS = Requests per second
NGINX, pronounced "engine x"
AWS = Amazon Web Services
The Nitty Gritty
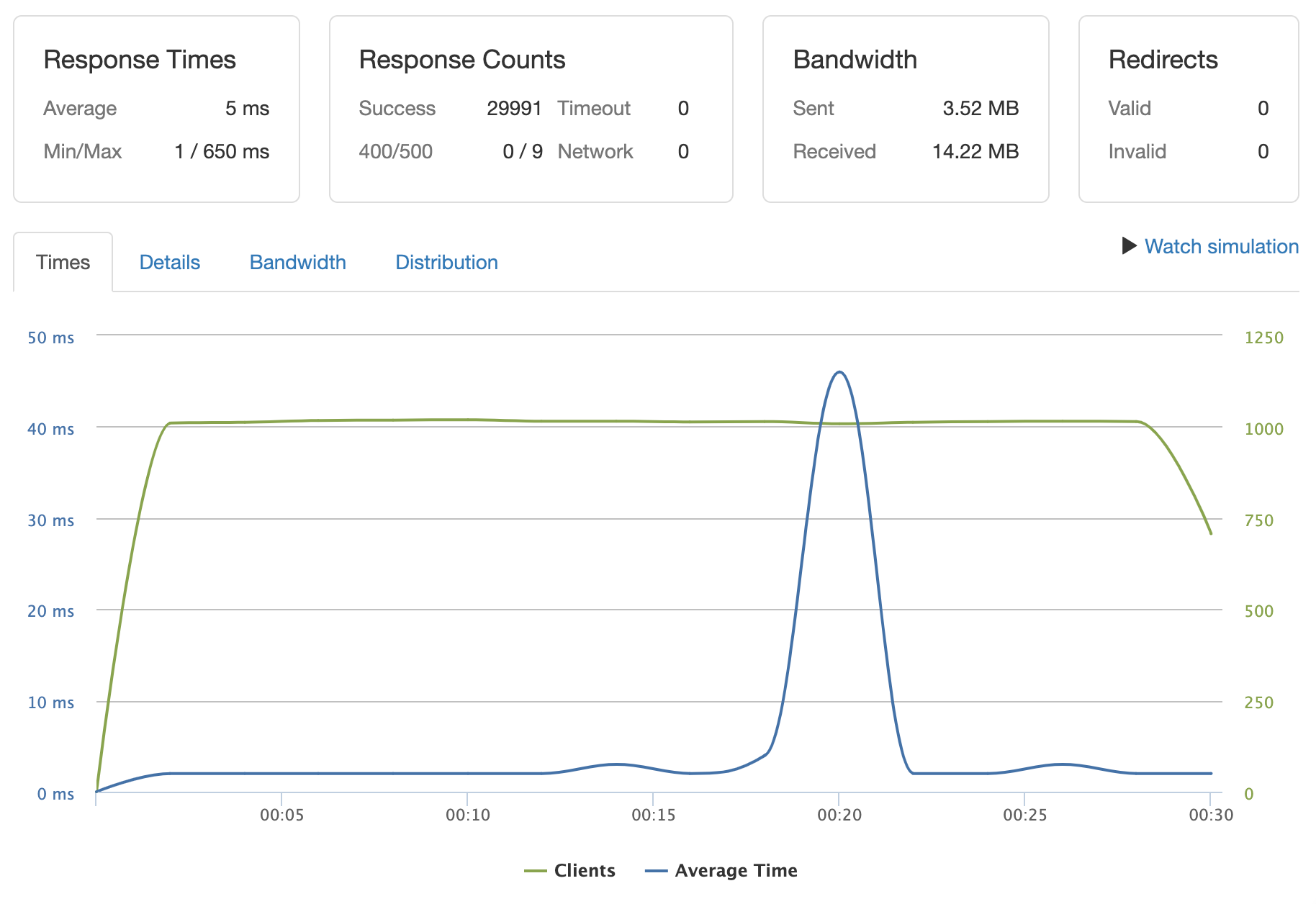
Random ID GET: scaled to 1k clients per second for random sampling of 100,000 records on /list and /meta GET endpoints with < 10 ms response time and < 0.003% error. Optimizations: indexing, load balancer with 4 services running
/reviews/%{*:1-100000}/meta :: 1000 clients per second :: 5 ms 0.003% error rate
/reviews/%{*:1-100000}/list :: 1000 clients per second :: 8ms 0.00% error rate
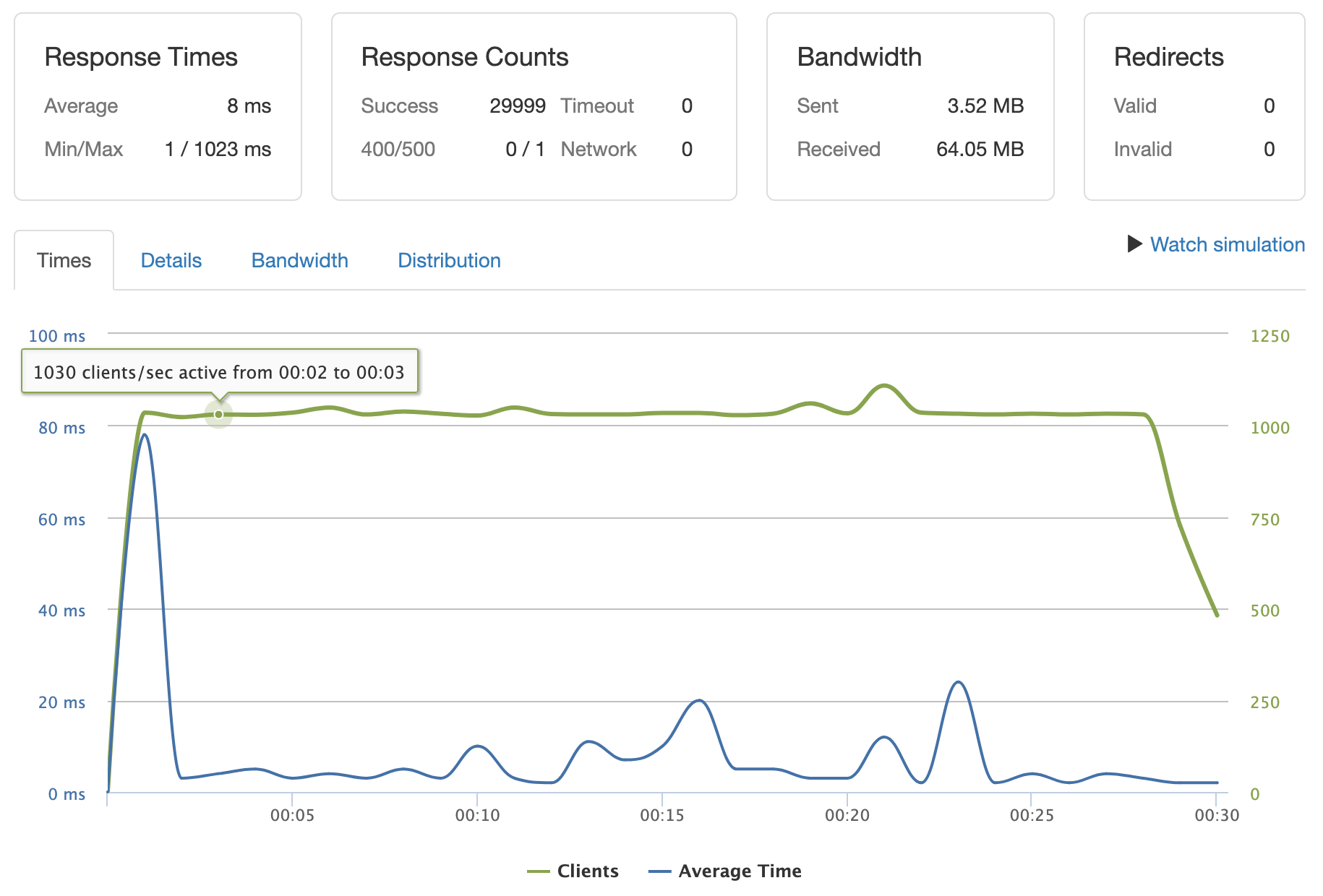
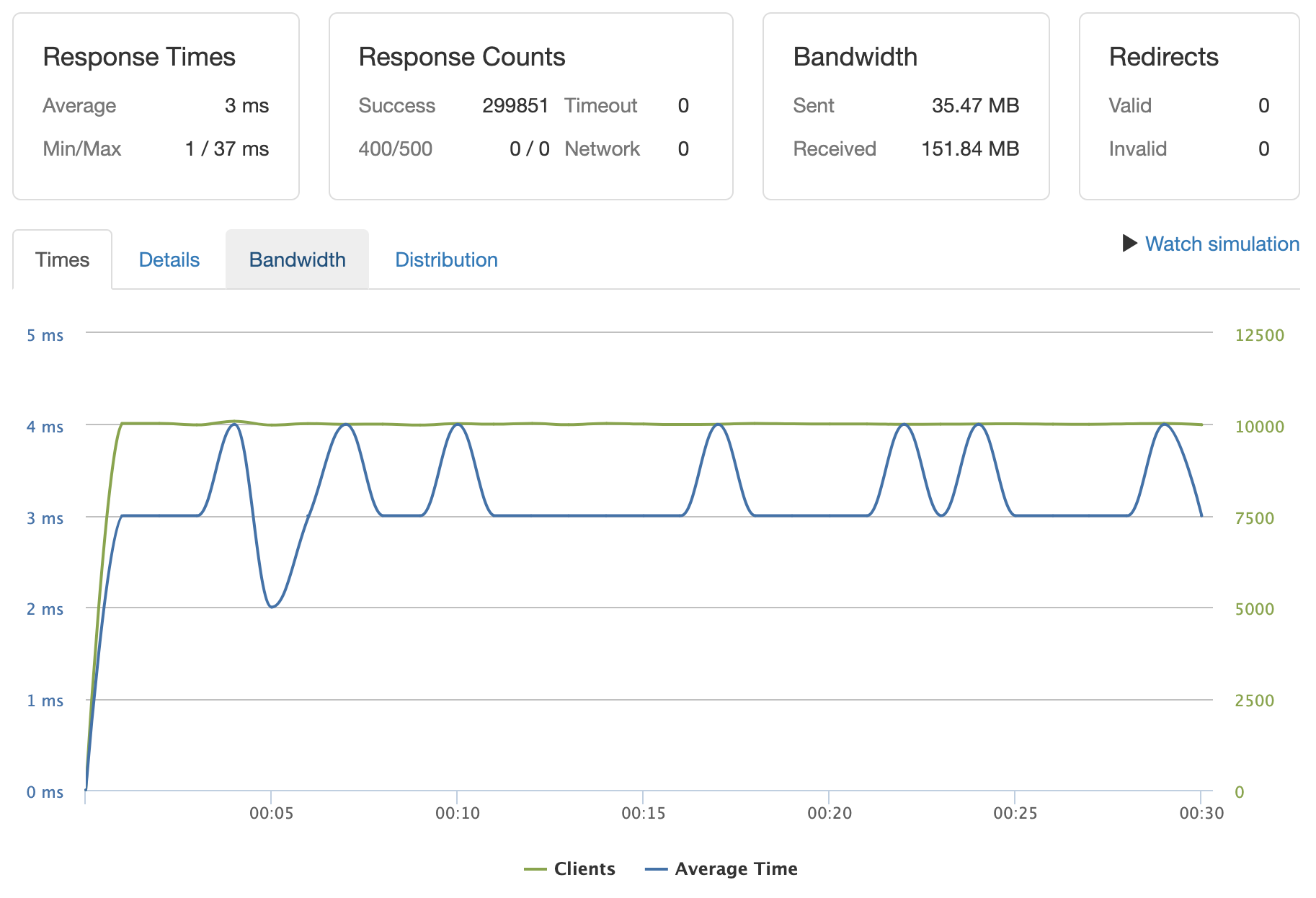
Repeating ID GET: Scaled to 10k clients per second for /meta requests on repeating IDs served by cache. 5k clients per second for /list
/reviews/%{*:100000-100010}/meta :: 10k clients per second :: 3ms with 149 errors ~0.0%
Why I chose Postgres?
- Data schema was highly defined. Did not need to adjust schema.
Query Structure
- Response times average < 50ms for any query. Meta was “heavier” endpoint with ~8 queries per call.
Challenges
- Building the meta query. Tried to do it in one query but opted to divide and conquer, which resulted in processing being done on server rather than db. I achieved MVP ahead of schedule but had to use more load balancers to scale my meta endpoint (higher cost).
Lessons
- Striving for a god-query seems to be worth the effort, but depends on how much time you have.
- Further improvements should be made based on user activity. To take it a step further, databases should be designed based on how the data will be used. 🤯
- Consider a separate db for the meta endpoint next.
Possible Improvements
- Separate db instance to serve the /meta endpoint
- ETL for meta data to remove calculations
Thoughts
This felt the closet to "real world application" thus far in Hack Reactor as we were using a lot of real world tools and encountering typical problems of a growing app. Many of these scaling services are automated and can be accomplished without knowing the nuts and bolts any more, but in typical Hack Reactor fashion we start from square one and build from there. It's an effective learning strategy for sure. I now know what load balancing actually means and I'm a little closer to being able to explain a reverse proxy server to a five year old - not quite though 😅.
This project gave me a strong appreciation for database whizzes. Structuring those complex queries is no easy task! It's pretty cool to think that SQL was introduced in 1979 and is STILL the standard database query language. I also felt more advanced than ever 🤣. Watching 6 virtual machines (4 Express servers, 1 NGINX load balancer, and 1 database instance) simultaneously respond to thousands of requests was just kind of fun to watch actually
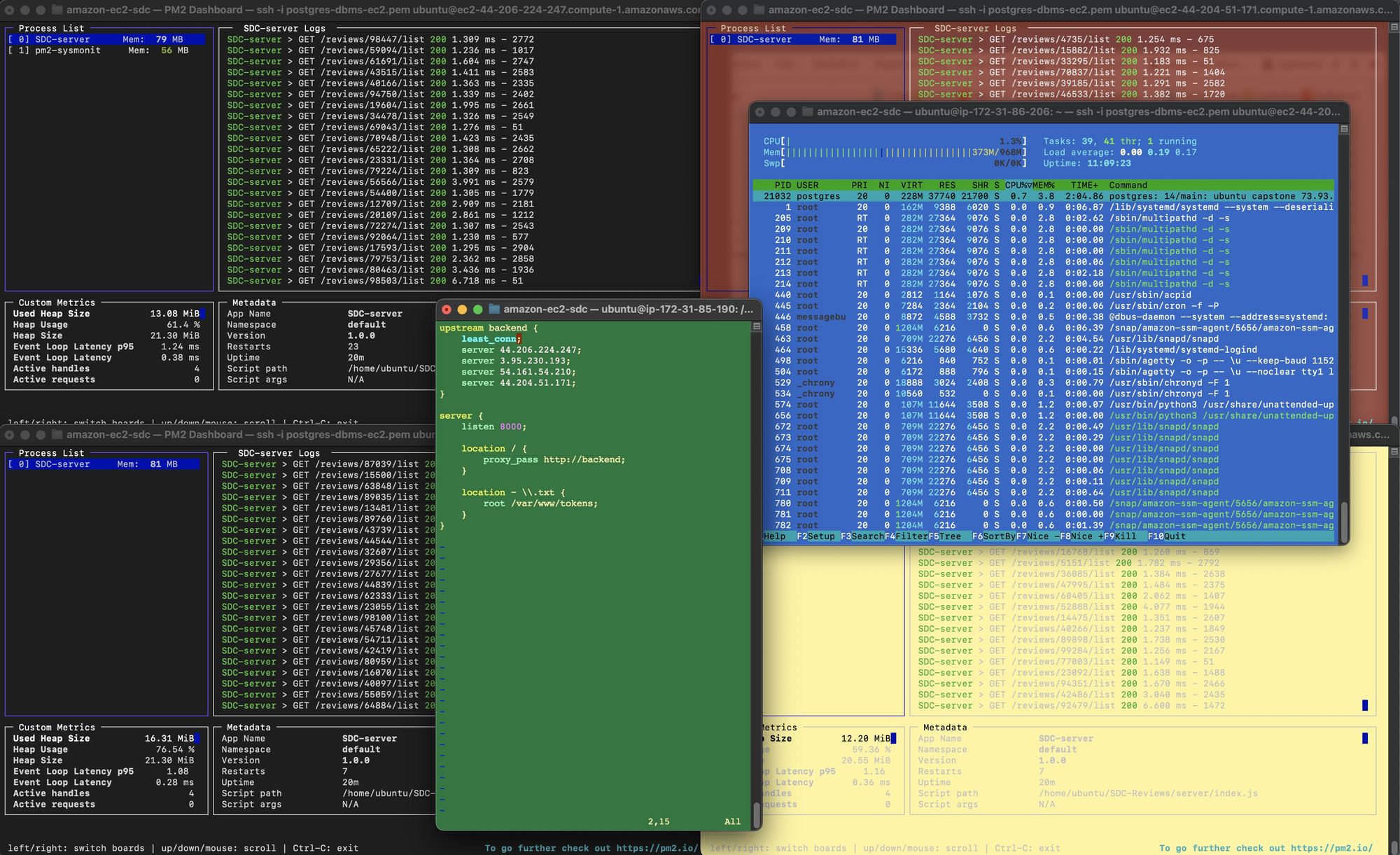
I remember spending all day trying to SSH into my first Digital Ocean droplet to host some python code for an instagram bot. Look how far I've come!


